一、SGC [2019]
《Simplifying Graph Convolutional Networks》
图卷积网络(
Graph Convolutional Network: GCN)及其变体已备受关注,并成为学习graph representations的实际标准方法。GCN主要从近期的深度学习方法中汲取灵感,因此可能继承了不必要的复杂性和冗余计算。在本文中,我们通过依次移除非线性激活函数、以及合并连续层之间的权重矩阵来减少这种过度复杂性。我们对所得的线性模型进行了理论分析,结果表明它对应于一个固定的低通滤波器(low-pass filter),其后接一个线性分类器。值得注意的是,我们的实验评估表明,这些简化在许多下游应用中不会对准确性产生负面影响。此外,所得模型可扩展到更大的数据集,具有自然的可解释性,并且与FastGCN相比,速度提升可达两个数量级。图卷积网络(
Graph Convolutional Network: GCN)是图上卷积神经网络(Convolutional Neural Network: CNN)的一种高效变体。GCN堆叠了多层的学习好的一阶谱滤波器(spectral filters),随后应用非线性激活函数来学习graph representations。最近,GCN及其后续变体在各个应用领域都取得了SOTA的结果,包括但不限于引文网络(citation networks)、社交网络(social networks)、应用化学(applied chemistry)、自然语言处理、以及计算机视觉。从历史上看,机器学习算法的发展遵循着从初始的简单性到需求驱动的复杂性(
need-driven complexity)这一清晰趋势。例如,线性感知机(linear Perceptron)的局限性推动了更复杂但表达能力更强的神经网络(或多层感知机,即MLP)的发展。类似地,简单的预定义的线性image filters最终演变为具有learned convolutional kernels的非线性CNN。由于额外的算法复杂性往往会使理论分析复杂化并模糊understanding,因此通常仅仅在simpler methods表现不佳的applications中引入复杂的算法。可以说,现实世界应用中的大多数分类器仍然是线性的(通常是logistic regression),它们易于优化且易于解释。然而,可能因为
GCN是在神经网络近期“复兴”之后提出的,所以它们往往是这一趋势的罕见例外。GCN建立在多层神经网络的基础上,从未是simpler(insufficient)的线性对应物的扩展。在本文中,我们观察到
GCN从其深度学习的沿袭中继承了相当大的复杂性,这对于要求较低的应用来说可能是繁重且不必要的。受历史上明显缺乏simpler前身的启发,我们旨在推导如果采用更“传统”的路径,本可以先于GCN出现的最简单线性模型。我们通过反复移除GCN层之间的非线性激活函数,并将所得函数合并为单个线性变换,来减少GCN的过度复杂性。我们通过实验表明,最终的线性模型在各种任务上表现出与GCN相当甚至更优的性能,同时计算效率更高,拟合的参数显著更少。我们将这种简化的线性模型称为Simple Graph Convolution: SGC。与非线性模型相比,
SGC具有直观的可解释性,我们从graph convolution的角度提供了理论分析。值得注意的是,SGC中的特征提取对应于应用于每个特征维度的单个fixed filter。《Semi-supervised classification with graph convolutional networks》通过实验观察到 “重新归一化技巧”(renormalization trick),即向图中添加自环,提高了准确性,我们证明该方法有效地缩小了图的谱域(graph spectral domain),当应用于SGC时会产生低通型滤波器(low-pass-type filter)。至关重要的是,这种滤波操作会在整个图中产生局部平滑的特征(《Spectral networks and locally connected networks on graphs》)。通过对引文网络和社交网络的节点分类基准数据集的实证评估,我们表明
SGC取得了与GCN和其他SOTA的图神经网络相当的性能。然而,它的速度明显更快,在我们评估的最大数据集(Reddit)上,甚至比FastGCN快达两个数量级。最后,我们证明SGC的有效性可推广到广泛的下游任务。特别是,在文本分类、用户地理定位(user geolocation)、关系抽取、以及zero-shot图像分类任务中,SGC即使不超越GCN-based的方法,也与之相当。代码可在Github上获取(https://github.com/Tiiiger/SGC)。
1.1 Simple Graph Convolution
我们遵循
《Semi-supervised classification with graph convolutional networks》在节点分类的上下文中介绍GCN(以及随后的SGC)。在这里,GCN将具有一些labeled nodes的graph作为输入,并为所有graph nodes生成label predictions。我们正式将这样的graph定义为
我们将度矩阵(
degree matrix)row-sum:图中的每个节点
one-hot向量unknown labels。
1.1.1 Graph Convolutional Networks
与
CNN或MLP类似,GCN通过multiple layers为每个节点的特征feature representation,随后将其用作线性分类器的输入。对于第graph convolution layer,我们将所有节点的input node representations用矩阵output node representations用initial node representations就是原始输入特征:其中
GCN layer的输入。一个
K-layer GCN等同于对图中每个节点的特征向量K-layer MLP,不同之处在于每个节点的hidden representation在每层开始时与其邻居进行平均。在每个graph convolution layer中,node representations通过三个阶段进行更新:feature propagation、linear transformation和pointwise nonlinear activation(见Figure 1)。为了清晰起见,我们详细描述每个步骤。特征传播(
Feature propagation):是GCN与MLP的区别所在。在每层开始时,每个节点更紧凑地,我们可以将整个图上的这种
update表示为一个简单的矩阵运算。令其中:
degree matrix。那么,上述公式中对所有节点的同时
update变为一个简单的稀疏矩阵乘法:直观地说,这一步沿着图的边对
hidden representations进行局部平滑,并最终促使局部连接的节点之间产生相似的predictions。特征变换和非线性转换(
Feature transformation and nonlinear transition):局部平滑后,GCN layer等同于标准的MLP。每层关联一个学到的权重矩阵smoothed hidden feature representations进行线性变换。最后,在输出feature representationReLU)。总之,第
representation的更新规则为:第
featurepropagation。
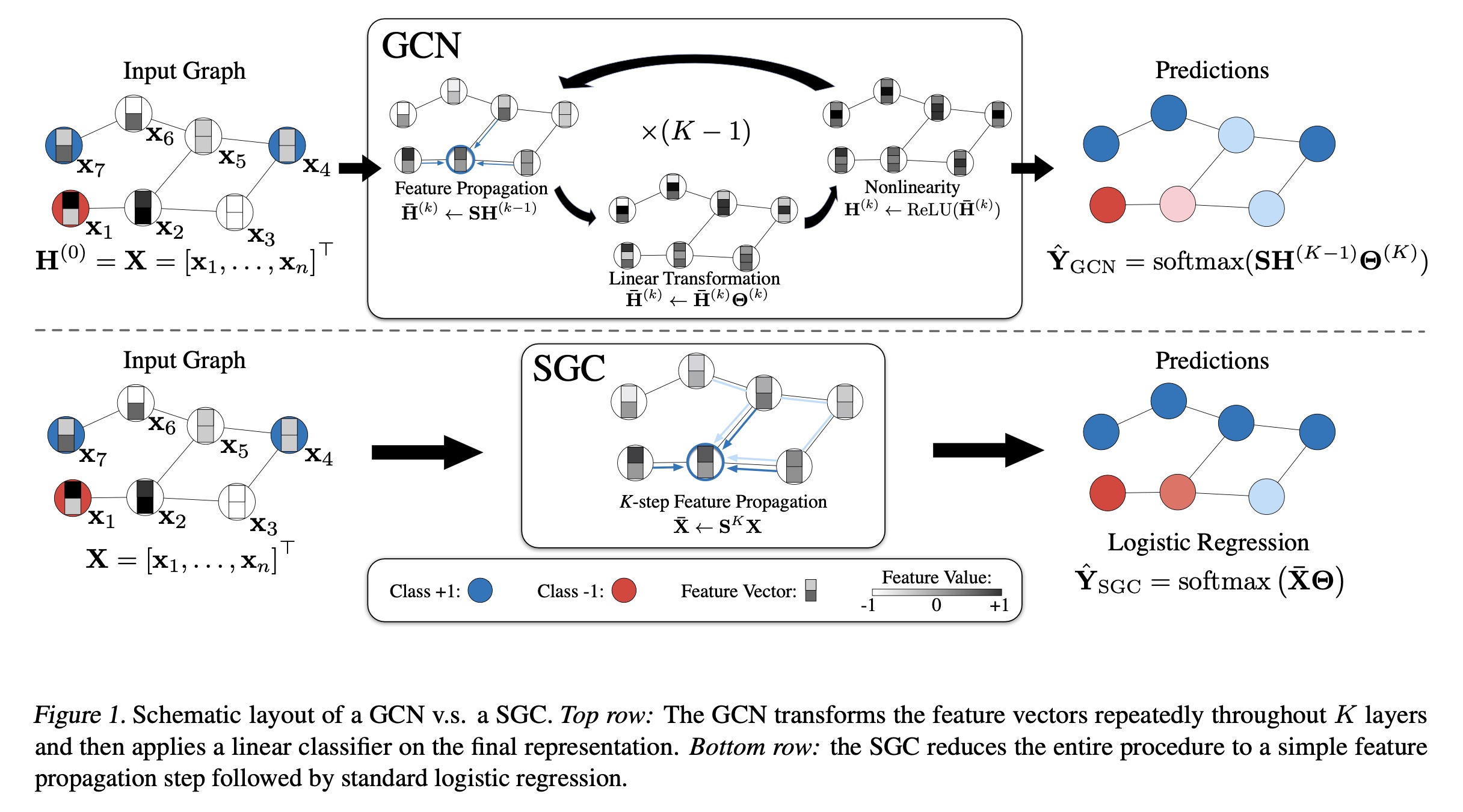
分类器:对于节点分类,与标准
MLP类似,GCN的最后一层使用softmax classifier来预测labels。将class predictions表示为K-layer GCN的class prediction其中:
1.1.2 Simple Graph Convolution
在传统的
MLP中,deeper layers通过允许creation of feature hierarchies来增加表达能力,例如第二层的特征建立在第一层特征的基础上。在GCN中,这些层还有第二个重要功能:在每一层中,hidden representations在one hop邻居之间进行平均。这意味着经过k−hops范围内的所有节点获取特征信息。这种效果类似于卷积神经网络,其中深度增加了内部特征的感受野(receptive field)。尽管卷积网络可以从增加的深度中受益匪浅,但通常MLP在超过3 ~ 4层后获益甚微。线性化(
Linearization)。我们假设GCN layers之间的非线性并非关键——但大部分好处来自局部平均(local averaging)。因此,我们移除各层之间的非线性转换函数,仅保留final softmax(以获得概率性的输出)。所得模型是线性的,但仍然具有K-layer GCN相同的increased的“感受野”:为了简化符号,我们可以将与归一化的邻接矩阵(
normalized adjacency matrix)我们将其称为
Simple Graph Convolution: SGC。逻辑回归(
Logistic regression):上式为SGC提供了自然且直观的解释。通过区分feature extraction和classifier,SGC由两部分组成:固定的(即无参数的)
feature extraction/smoothing组件:跟线性逻辑回归分类器:
由于
feature pre-processing)步骤,并且模型的整个训练简化为对预处理后的特征multi-class logistic regression)。Optimization细节:逻辑回归的训练是一个经过充分研究的凸优化问题,可以使用任何高效的二阶方法或随机梯度下降(《Large-scale machine learning with stochastic gradient descent》)进行。假设graph connectivity pattern足够稀疏,SGD自然可以扩展到非常大的图规模,并且SGC的训练速度比GCN快得多。
1.2 频谱分析
我们现在从
graph convolution的角度研究SGC。我们证明SGC对应于图频谱域(graph spectral domain)上的一个固定滤波器(fixed filter)。此外,我们表明向原始图添加自环(即renormalization trick)可有效缩小underlying graph spectrum。在这个scaled domain上,SGC充当低通滤波器(low-pass filter),在图上生成平滑的特征(smooth features)。因此,邻近节点往往具有相似的representations,从而产生相似的predictions。
1.2.1 图卷积预备知识
与欧几里得域类似,图傅里叶分析(
graph Fourier analysis)依赖于图拉普拉斯矩阵(graph Laplacians)的谱分解(spectral decomposition)。图拉普拉斯矩阵eigendecomposition) :其中:
拉普拉斯矩阵的特征分解使我们能够在
graph domain上定义等效的傅里叶变换,其中特征向量表示傅里叶模式(Fourier modes),特征值表示图的频率。在此框架下,设graph convolution运算为:其中:
spectral filter的系数。注意:
Graph convolutions可以用拉普拉斯矩阵的其中
在这种情况下,滤波器系数对应于拉普拉斯特征值的多项式,即
图卷积网络(
《Semi-supervised classification with graph convolutional networks》)采用GCN卷积运算:在最终设计中,
《Semi-supervised classification with graph convolutional networks》将矩阵renormalization trick)。最后,通过将卷积推广到处理
d-channel input中的多个滤波器,并在每层之间使用非线性激活函数,我们得到了GCN传播规则。
1.2.2 SGC与低通滤波
GCN中推导的初始的一阶切比雪夫滤波器对应于propagation matrixfeature propagation意味着滤波器系数Figure 2展示了与为解决一阶切比雪夫滤波器可能存在的数值问题,
《Semi-supervised classification with graph convolutional networks》提出了renormalization trick。本质上,它包括将propagation矩阵称为augmented normalized adjacency matrixaugmented normalized Laplacian我们现在分析
normalized Laplacian的频谱(特征值)。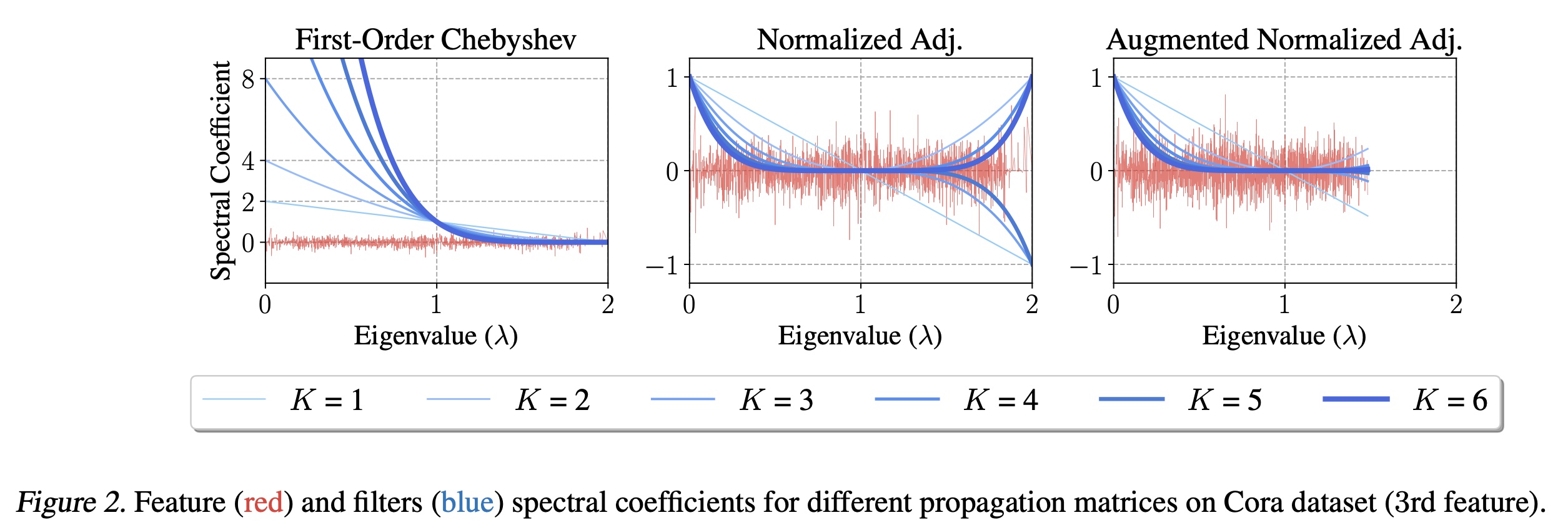
定理
1:设augmented adjacency matrix,对应度矩阵为定理
1表明,添加自环(normalized graph Laplacian的最大特征值变小(证明见补充材料)。Figure 2描绘了Cora数据集上normalized adjacencyfeature propagation对应于频谱范围2缩小到约1.5,从而消除了负系数的影响。此外,这种缩放后的频谱允许取
propagation matrix的不同选择进行了实证评估。
1.3 实验
我们首先在引文网络和社交网络上评估
SGC,然后将实证分析扩展到广泛的下游任务。
1.3.1 引文网络与社交网络
我们在
Cora、Citeseer和Pubmed引文网络数据集(Table 2)上评估SGC的半监督节点分类性能。通过使用SGC对Reddit(Table 3)的社区结构进行归纳性的预测来补充引文网络分析,Reddit包含更大的图。数据集统计信息汇总在Table 1中。
数据集与实验设置:
在引文网络上,我们使用
Adam训练SGC达100个epoch,学习率为0.2。此外,我们使用weight decay,并通过hyperopt在公开的split validation set上进行60次迭代从而调优每个数据集的超参数。引文网络实验以直推式(transductively)进行。在
Reddit数据集上,我们使用L-BFGS训练SGC,不使用正则化,且训练在2 steps内收敛。我们按照《FastGCN: Fast Learning with Graph Convolutional Networks via Importance Sampling》的方法进行归纳式(inductively)评估:在仅包含训练节点的子图上训练SGC,并在原始图上测试。
在所有数据集上,我们根据收敛行为和验证准确来调优
epoch数。baseline:对于引文网络,我们将
SGC与GCN、GAT、FastGCN、LNet、AdaLNet和DGI进行比较。其中这些基线模型都采用公开实现的版本。由于GIN最初未在引文网络上评估,我们按照《How powerful are graph neural networks?》来实现GIN,并使用hyperopt在60 iterations内调优weight decay和学习率。此外,我们手动调优hidden dimension。对于
Reddit,我们将SGC与GaAN、GraphSAGE的监督和无监督变体、FastGCN和DGI的报告性能进行比较。Table 3还突出显示了每种方法的feature extraction step的设置。值得注意的是,SGC不涉及学习,因为eature extraction stepno-learning方法均在之后使用labels来训练逻辑回归模型。
性能:根据
Table 2和Table 3的结果,我们得出SGC具有很强竞争力的结论。Table 2显示:SGC在引文网络上的性能可与GCN和SOTA的图网络相媲美。特别是在Citeseer上,SGC比GCN高约1%,我们认为这种性能提升是由于SGC参数更少,因此过拟合更少。值得注意的是,
GIN由于过拟合表现稍差。此外,
LNet和AdaLNet在引文网络上不稳定。
在
Reddit上,Table 3显示SGC比之前的基于采样的GCN变体(SAGE-GCN和FastGCN)高出1%以上。值得注意的是,
《Deep Graph InfoMax》报告称,随机初始化的DGI encoder的性能几乎与trained encoder相当;然而,这两种模型在Reddit上的表现均不如SGC。这一结果可能表明,DGI encoder中的额外权重和非线性即使不是完全有害的,也是多余的。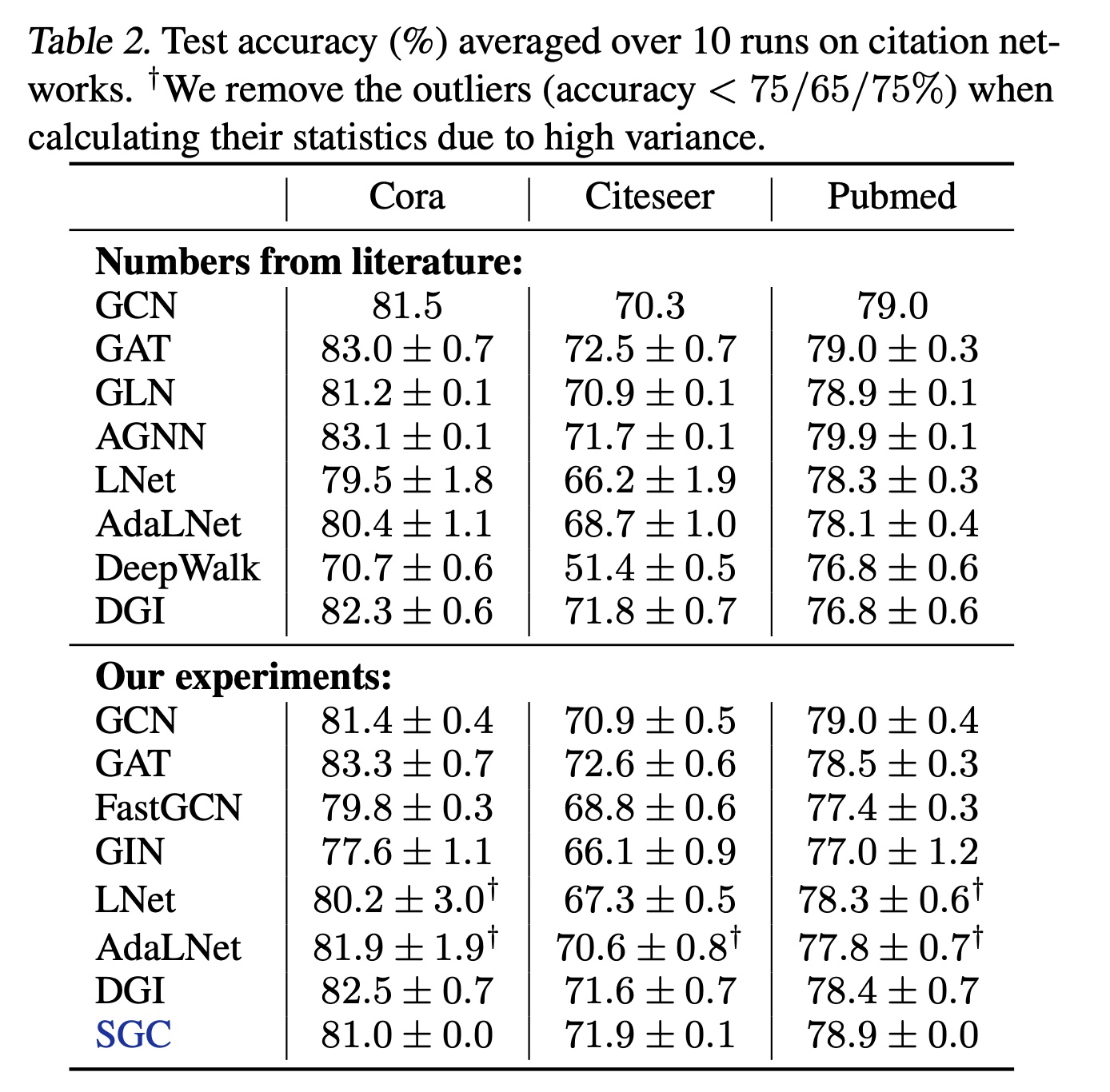

效率:在
Figure 3中,我们绘制了SOTA的图网络在Pubmed数据集和Reddit数据集上的性能、以及它们其相对于SGC的训练时间的关系。特别地,我们预计算SGC的训练时间考虑了此precomputation时间。我们在NVIDIA GTX 1080 Ti GPU上测量训练时间,基准细节见补充材料。在大型图(如
Reddit)上,由于内存需求过高,GCN无法训练。先前的方法通过采样减少邻域大小(FastGCN、GraphSage)或限制模型大小(DGI)来解决这一限制。通过应用固定滤波器并预计算SGC最小化内存使用,仅在训练期间学习单个权重矩阵。由于sparse-dense矩阵乘法来计算Figure 3显示,SGC的训练速度比基于快速采样的方法快两个数量级,同时性能几乎没有下降。
1.3.2 下游任务
我们将实证评估扩展到
5个下游应用以研究SGC的适用性:文本分类、半监督的用户地理定位、关系抽取、zero-shot图像分类、以及graph分类。实验设置见补充材料。文本分类(
Text classification):为文档分配标签。《Graph convolutional networks for text classification》使用两层GCN,将文档和单词均视为图中节点,从而实现了SOTA的结果。word-word的边权重为pointwise mutual information: PMI,word-document的边权重为归一化的TF-IDF分数。Table 4显示,SGC(5个基准数据集上与他们的模型相当,同时快达83.6倍。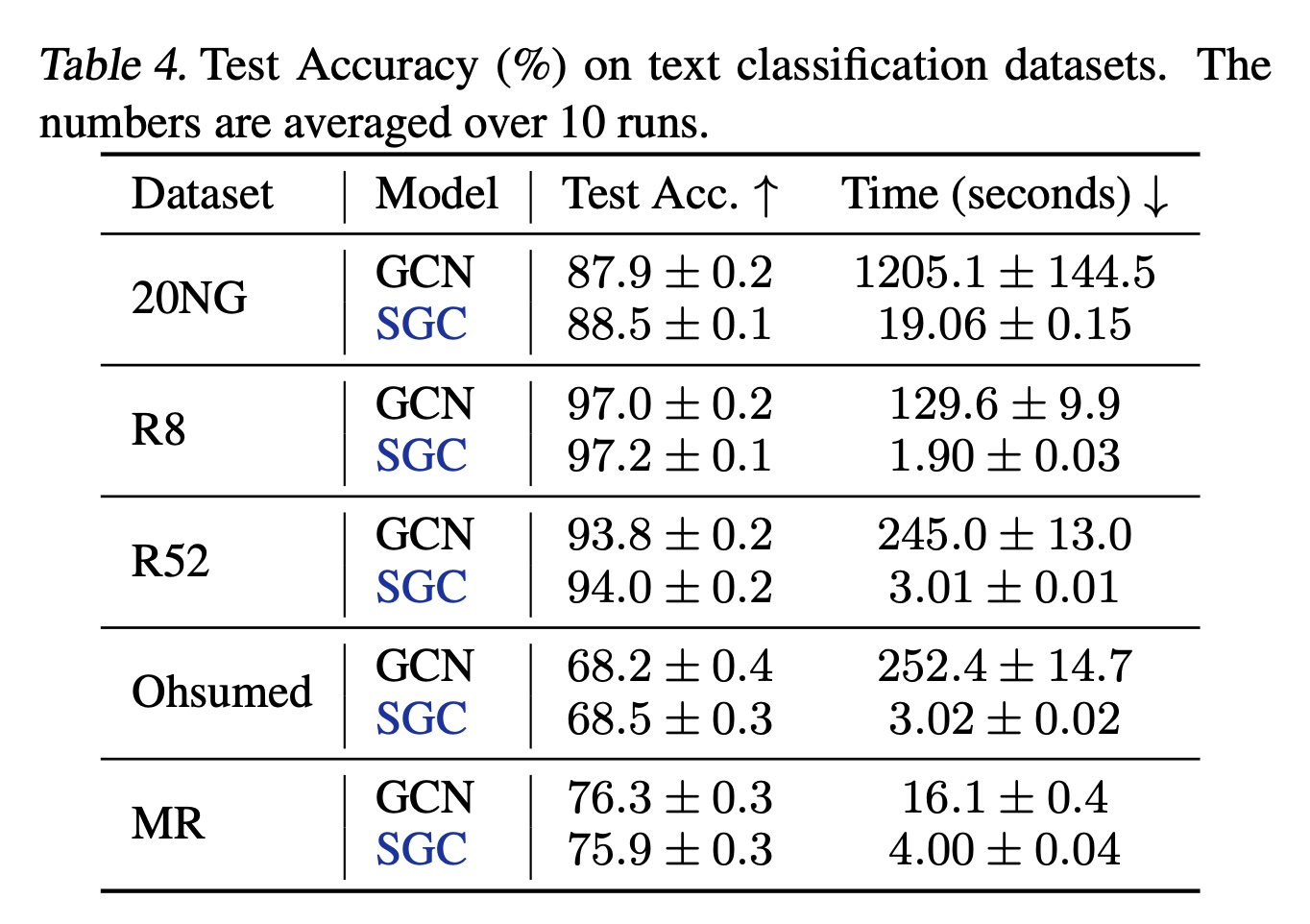
半监督用户地理定位(
Semi-supervised user geolocation):根据用户的帖子、用户之间的连接、以及少量标记用户,定位社交媒体上用户的“home” position。《Semi-supervised user geolocation via graph convolutional networks》在此任务上应GCNs with highway connections,取得了接近SOTA的结果。Table 5显示,在《Semi-supervised user geolocation via graph convolutional networks》在的框架下,SGC在GEOTEXT、TWITTER-US和TWITTER-WORLD上优于GCN with highway con- nections,同时在TWITTER-WORLD上节省了30多个小时。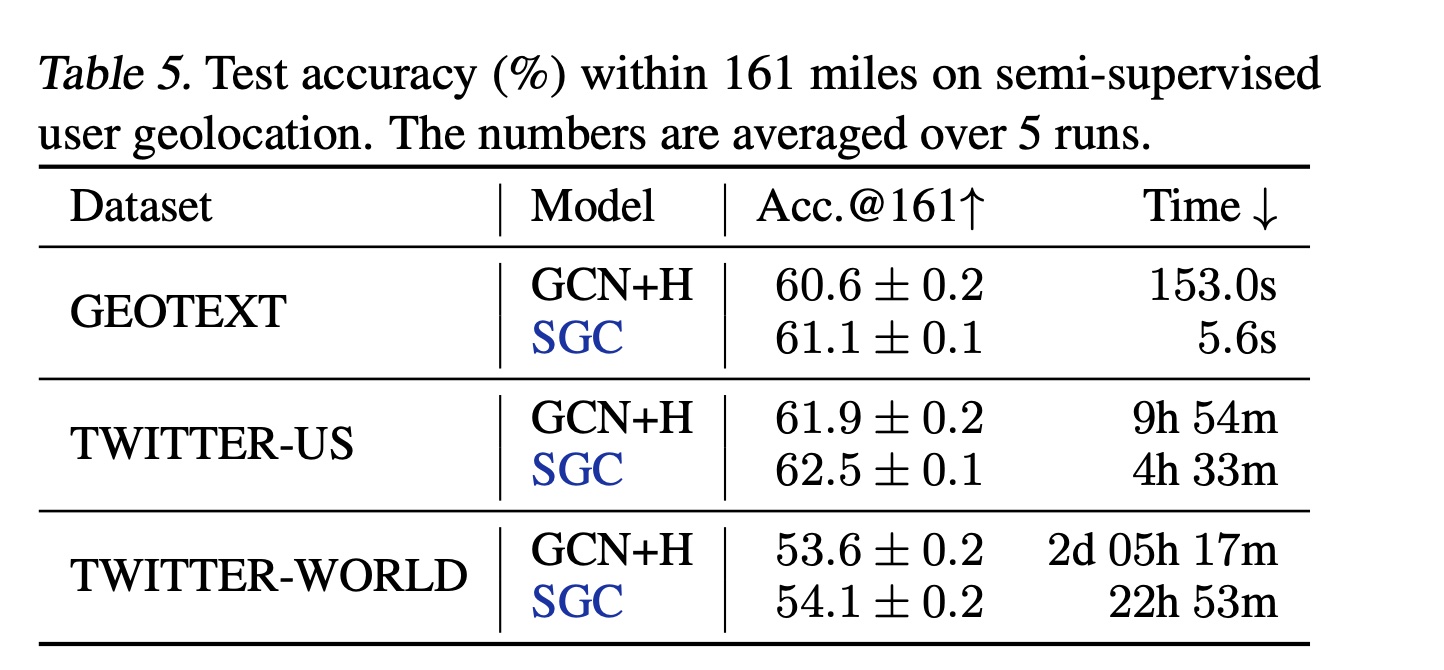
关系抽取(
Relation extraction):涉及预测句子中主语和宾语之间的关系。《Graph convolution over pruned dependency trees improves relation extraction》提出C-GCN,其使用LSTM后跟GCN和MLP。我们将GCN替换为SGC(C-SGC。Table 6显示,C-SGC在TACRED上创下新的SOTA。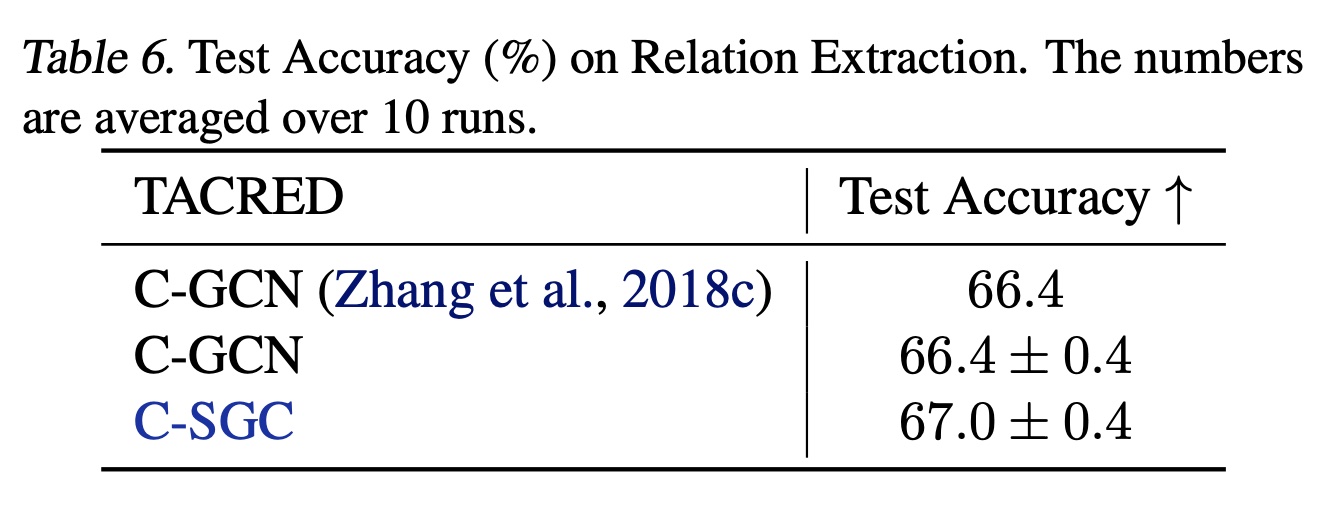
零样本图像分类(
Zero-shot image classification):无法访问test categories中任何图像或者label的情况下,学习一个图像分类器。GCNZ使用GCN根据WordNet中的关系将category names映射到image feature domain,并找到与query image feature vector最相似的类别。Table 7显示,将GCN替换为MLP后跟SGC可提高性能,同时将参数数量减少55%。我们发现,MLP feature extractor对于将pretrained GloVe vectors映射到ResNet-50提取的视觉特征空间是必要的。同样,这一下游应用表明,学到的graph convolution filters是多余的;类似于《Classifier and exemplar synthesis for zero-shot learning》的观察,即GCN可能并非必要。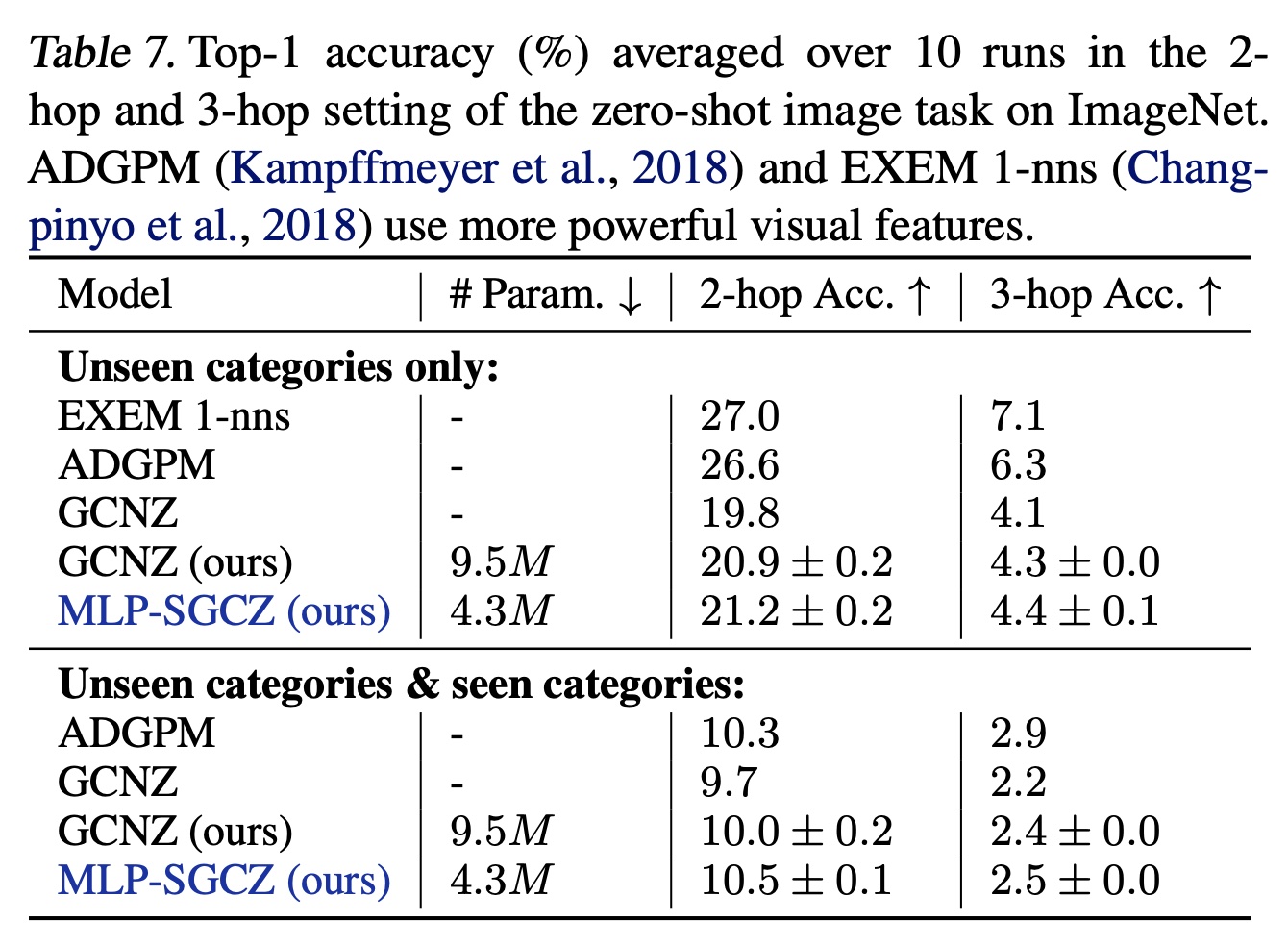
图分类(
Graph classification):要求模型使用graph structure对graph进行分类。《How powerful are graph neural networks?》从理论上表明,GCN不足以区分某些图结构,并表明他们的GIN更具表达能力,在各种图分类数据集上取得了SOTA的结果。我们将DCGCN中的GCN替换为SGC,在NCI1和COLLAB数据集上分别获得71.0%和76.2%的准确率,与GCN相当,但远低于GIN。类似地,在QM8量子化学数据集上,更先进的AdaLNet和LNet在QM8上的MAE为0.01,显著优于SGC的0.03的MAE。
1.4 结论
为了更好地理解和解释
GCN的机制,我们探索了图卷积模型的最简单可能形式——SGC。该算法几乎是trivial的:一个基于图的预处理步骤,随后接标准的多类逻辑回归。然而,SGC的性能在广泛的图学习任务中与GCN和SOTA的图神经网络模型相当,甚至更优。此外,通过预计算固定的特征提取器Reddit数据集上,SGC的训练速度比基于采样的GCN变体快两个数量级。除了实证分析,我们还从卷积角度分析了
SGC,证明其在频谱域上相当于一个低通型滤波器。低通型滤波器捕获低频信号,这对应于在图上smoothing features。我们的分析还解释了renormalization trick的实证效果,表明缩小频谱域如何产生支撑SGC的低通型滤波器。最终,
SGC的优异性能揭示了GCN的本质:其表达能力很可能主要来自于repeated graph propagation(SGC保留了这一点),而非nonlinear feature extraction(SGC未采用)。鉴于其实证性能、效率和可解释性,我们认为
SGC至少在三个方面对社区具有重要价值:(1):作为首选模型,尤其是节点分类任务。(2):作为与未来graph learning models比较的简单基线。(3):作为graph learning未来研究的起点——回归机器学习从简单模型发展为复杂模型的历史实践。